CosyEdit: Unlocking End-to-End Speech Editing Capability from Zero-Shot Text-to-Speech Models
🎧 Demo Page | 📜 Paper | 💻 Code
Abstract: Automatic speech editing aims to modify spoken content based on textual instructions, yet traditional cascade systems rely on explicit temporal alignment and complex preprocessing. To address these limitations, we propose CosyEdit, an end-to-end speech editing model adapted from CosyVoice through task-specific post-training and a complementary training paradigm, which internalizes text--speech alignment while ensuring high consistency between the speech before and after editing. Trained on only 250 hours of supervised data from our curated GigaEdit dataset, our 400M-parameter model achieves reliable speech editing performance. Extensive evaluations show that CosyEdit not only outperforms several billion-parameter language model baselines but also approaches state-of-the-art cascade systems. These results show that robust and efficient speech editing can be unlocked from a zero-shot TTS model through post-training, offering a cost-effective end-to-end solution for high-quality speech editing.
Key Advantages:
-
Comfortable Speech Editing ☕
No external speech–text alignment tools, no complex editing algorithms— everything is handled by an end-to-end model, just one-step editing. -
Native Multi-Span Editing ✂️
Natively supports insertion, deletion, and substitution across multiple spans within a single utterance, all completed in one inference pass. -
Low-Cost, High-Performance ⚡
Unlocks strong speech editing capabilities from existing zero-shot TTS models, delivering competitive performance with small model size and minimal training cost.

Contents
Cascade Speech Editing vs. End-to-End Speech Editing
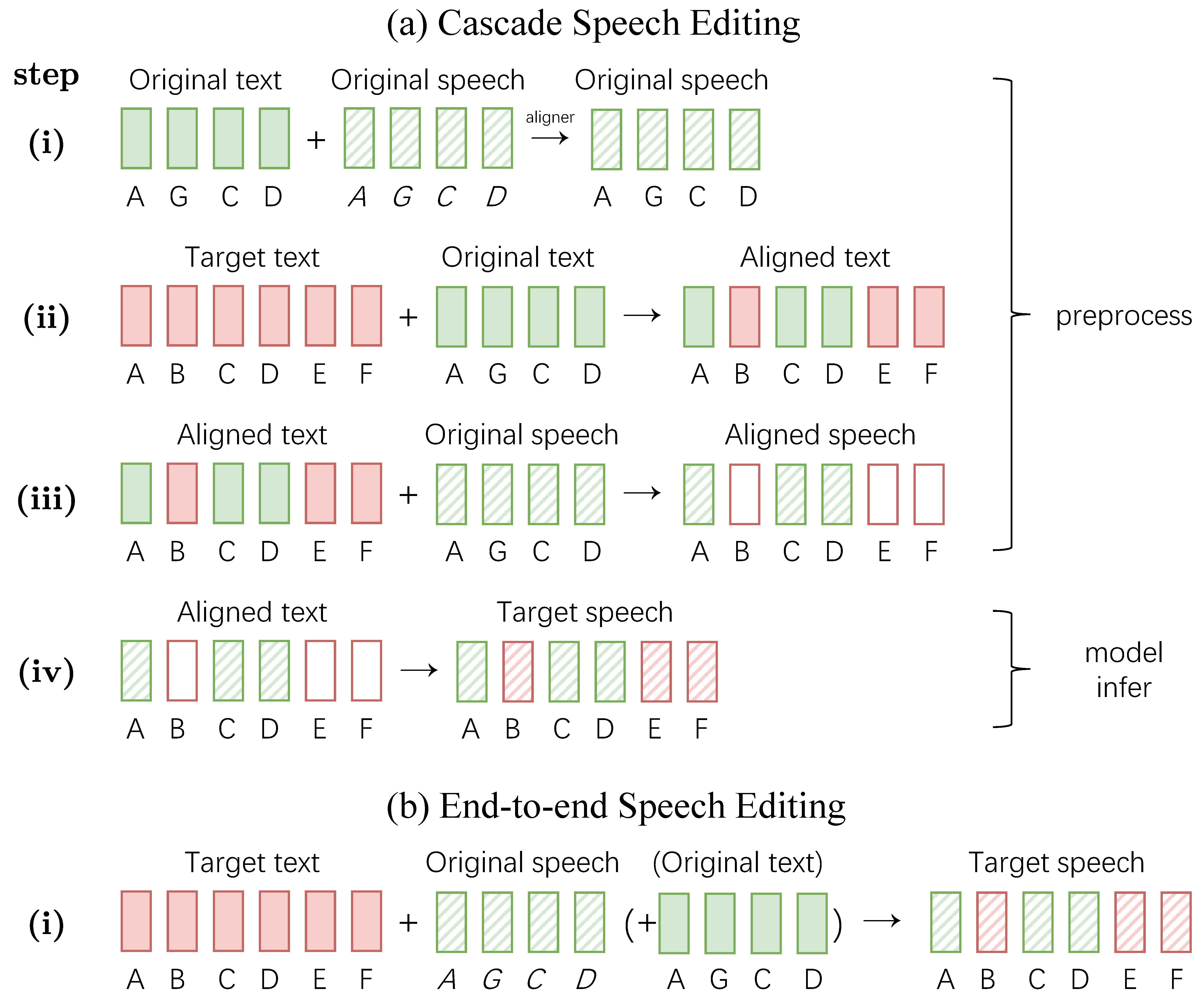
Cascade Speech Editing Systems:
Step 1) Speech–Text Temporal Alignment. Use an external forced aligner (e.g., Montreal Forced Aligner) to obtain timestamp-level temporal alignment between the original speech signal and its corresponding transcript.
Step 2) Text Edit Span Detection. Compare the original text with the target text to identify the textual regions that need to be inserted, deleted, or substituted.
Step 3) Speech Segmentation Based on Edits. Leverage the temporal alignment and detected text edit spans to determine the corresponding speech boundaries and split the input speech into preserved and editable segments.
Step 4) Edited Speech Generation and Integration. Apply speech editing models to generate the modified speech segments and seamlessly integrate them with the preserved original speech to produce the final edited utterance.
End-to-End Speech Editing Models:
Just One Step: Directly generate the edited speech from the original speech and the target transcript, optionally conditioning on the original text, without relying on any external alignment tools or complex preprocessing pipelines.
Overview of CosyEdit
(a) Example of four editing tasks for constructing the speech editing training dataset GigaEdit, which is built based on the GigaSpeech-S dataset and includes insertion task, deletion task, substitution task, and multi-edit task.
(b) Schematic diagram of CosyEdit. S, E and T represent the markers of "start of the sequence", "end of the sequence" and "transition token" respectively. Dashed lines indicate the autoregressive decoding.
(c) Enlarged view of the GOT-CFM module, conditioned on speaker embedding $\mathbf{v}$, concatenated semantic tokens $\mu_Z$, concatenated speech features $\tilde{Z}$, and intermediate state $Z_t$ at timestep $t$. Here, $\mu_Z = [\mu_{\mathrm{ori}}, \mu_{\mathrm{tar}}]$ and $\tilde{Z} = [M_{\mathrm{ori}}, \tilde{M}_{\mathrm{tar}}]$, where $\tilde{M}_{\mathrm{tar}}$ denotes the fully masked target mel-spectrogram.
Insertion Task
Example 1
| Ground Truth | CosyEdit (Ours) | FluentSpeech | VoiceCraft | SSR-Speech | Step-Audio-EditX | Mimo-Audio | Ming-UniAudio |
|---|---|---|---|---|---|---|---|
Example 2
| Ground Truth | CosyEdit (Ours) | FluentSpeech | VoiceCraft | SSR-Speech | Step-Audio-EditX | Mimo-Audio | Ming-UniAudio |
|---|---|---|---|---|---|---|---|
Deletion Task
Example 1
| Ground Truth | CosyEdit (Ours) | FluentSpeech | VoiceCraft | SSR-Speech | Step-Audio-EditX | Mimo-Audio | Ming-UniAudio |
|---|---|---|---|---|---|---|---|
Example 2
| Ground Truth | CosyEdit (Ours) | FluentSpeech | VoiceCraft | SSR-Speech | Step-Audio-EditX | Mimo-Audio | Ming-UniAudio |
|---|---|---|---|---|---|---|---|
Substitution Task
Example 1
| Ground Truth | CosyEdit (Ours) | FluentSpeech | VoiceCraft | SSR-Speech | Step-Audio-EditX | Mimo-Audio | Ming-UniAudio |
|---|---|---|---|---|---|---|---|
Example 2
| Ground Truth | CosyEdit (Ours) | FluentSpeech | VoiceCraft | SSR-Speech | Step-Audio-EditX | Mimo-Audio | Ming-UniAudio |
|---|---|---|---|---|---|---|---|
Multi-Edit Task
Example 1
| Ground Truth | CosyEdit (Ours) | FluentSpeech | VoiceCraft | SSR-Speech | Step-Audio-EditX | Mimo-Audio | Ming-UniAudio |
|---|---|---|---|---|---|---|---|
Example 2
| Ground Truth | CosyEdit (Ours) | FluentSpeech | VoiceCraft | SSR-Speech | Step-Audio-EditX | Mimo-Audio | Ming-UniAudio |
|---|---|---|---|---|---|---|---|
Acknowledgements
This work builds upon several excellent open-source projects:
- We borrowed a lot of code from CosyVoice.
- We borrowed a lot of code from WeNet.
- The template for this demo page is adapted from FunAudioLLM.
We are deeply grateful to the authors and contributors of these projects for their outstanding work and for making their code publicly available, which has been instrumental in advancing our research.
Disclaimer
The content provided above is for academic purposes only and is intended to demonstrate technical capabilities. Some examples are sourced from the internet. If any content infringes on your rights, please contact us to request its removal.